Improve documentations. (#20)
* Improve help message of model preload * Update development/scripts/triton.sh * Improve documents * Update deployment.md * Update deployment.mdadd-more-languages
parent
9d92821cf5
commit
d5d58fbbec
|
|
@ -10,4 +10,4 @@ An opensource / on-prem alternative to GitHub Copilot
|
||||||
|
|
||||||
## Deployment
|
## Deployment
|
||||||
|
|
||||||
See [deployment](./deployment/README.md)
|
See [deployment](./docs/deployment.md)
|
||||||
|
|
|
||||||
|
|
@ -1,13 +0,0 @@
|
||||||
## Prerequisites
|
|
||||||
You need install following dependencies
|
|
||||||
* docker `>= 17.06`
|
|
||||||
* An NVIDIA GPU with enough VRAM to run the model you want.
|
|
||||||
* [NVIDIA Docker Driver](https://docs.nvidia.com/datacenter/tesla/tesla-installation-notes/index.html)
|
|
||||||
|
|
||||||
## Setup
|
|
||||||
|
|
||||||
`docker-compose up`
|
|
||||||
|
|
||||||
Open Admin Panel [http://localhost:8501](http://localhost:8501)
|
|
||||||
|
|
||||||

|
|
||||||
|
|
@ -1,6 +1,9 @@
|
||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
set -e
|
set -e
|
||||||
|
|
||||||
|
if [ -d "$MODEL_NAME" ]; then
|
||||||
|
MODEL_DIR="$MODEL_NAME"
|
||||||
|
else
|
||||||
# Get model dir.
|
# Get model dir.
|
||||||
MODEL_DIR=$(python3 <<EOF
|
MODEL_DIR=$(python3 <<EOF
|
||||||
from huggingface_hub import snapshot_download
|
from huggingface_hub import snapshot_download
|
||||||
|
|
@ -8,6 +11,7 @@ from huggingface_hub import snapshot_download
|
||||||
print(snapshot_download(repo_id='$MODEL_NAME', allow_patterns='triton/**/*', local_files_only=True))
|
print(snapshot_download(repo_id='$MODEL_NAME', allow_patterns='triton/**/*', local_files_only=True))
|
||||||
EOF
|
EOF
|
||||||
)
|
)
|
||||||
|
fi
|
||||||
|
|
||||||
# Set model dir in triton config.
|
# Set model dir in triton config.
|
||||||
sed -i 's@${MODEL_DIR}@'$MODEL_DIR'@g' $MODEL_DIR/triton/fastertransformer/config.pbtxt
|
sed -i 's@${MODEL_DIR}@'$MODEL_DIR'@g' $MODEL_DIR/triton/fastertransformer/config.pbtxt
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,23 @@
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
You need install following dependencies
|
||||||
|
* docker `>= 17.06`
|
||||||
|
* An NVIDIA GPU with enough VRAM to run the model you want.
|
||||||
|
* [NVIDIA Docker Driver](https://docs.nvidia.com/datacenter/tesla/tesla-installation-notes/index.html)
|
||||||
|
|
||||||
|
## Setup Tabby Server with `docker-compose`.
|
||||||
|
|
||||||
|
1. Goto [`deployment`](../deployment) directory
|
||||||
|
2. Execute `docker-compose up`.
|
||||||
|
|
||||||
|
## Tabby Client
|
||||||
|
|
||||||
|
There're several ways to talk to the Tabby Server.
|
||||||
|
|
||||||
|
### Tabby Admin Panel [http://localhost:8501](http://localhost:8501)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### OpenAPI [http://localhost:5000](http://localhost:5000)
|
||||||
|
|
||||||
|
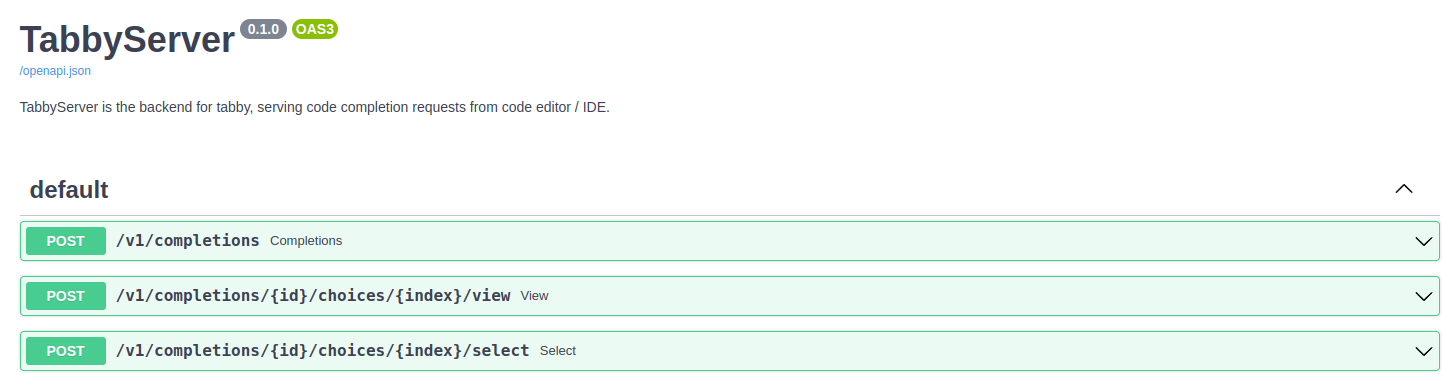
|
||||||
|
|
@ -9,7 +9,12 @@ class Arguments:
|
||||||
repo_id: str = field(
|
repo_id: str = field(
|
||||||
metadata={"help": "Huggingface model repository id, e.g TabbyML/NeoX-160M"}
|
metadata={"help": "Huggingface model repository id, e.g TabbyML/NeoX-160M"}
|
||||||
)
|
)
|
||||||
prefer_local_files: bool = True
|
prefer_local_files: bool = field(
|
||||||
|
metadata={
|
||||||
|
"help": "Whether prefer loading local files (skip remote version check if local files are valid)."
|
||||||
|
},
|
||||||
|
default=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
def parse_args():
|
def parse_args():
|
||||||
|
|
|
||||||
Loading…
Reference in New Issue